|
Tipps & Tricks zu gängiger Software... |
NTBackup |
Voraussetzungen: Kenntnisse im Umgang mit Taskplaner und NTBackup
Sie haben in der Vergangenheit mit Windows 2000 als Betriebssystem gearbeitet und die Vorteile des Taskplaners und des Windows-Sicherungsprogramms NTBackup zu schätzen gelernt. Nach dem Umstieg auf Windows XP Home mussten Sie allerdings mit Entsetzen feststellen, dass dieses Dienstprogramm nicht mehr zur Verfügung gestellt wird.
NTBackup unter Windows XP einbinden
NTBackup wird dem Benutzer unter Windows XP Home erst einmal vorenthalten. Wer auch unter diesem Betriebssystem mit dem bewährten Windows-Sicherungsprogramm arbeiten möchte, muss das Dienstprogramm von einer beliebigen Windows XP-CD (Home oder Professional) aus dem Verzeichnis "X:\VALUEADD\MSFT\NTBACKUP\" unter XP installieren. Einschränkungen im Hinblick auf den Funktionsumfang unter der Home-Edition (keine komplette Systemsicherung usw.) entnehmen Sie der in diesem Verzeichnis befindlichen Datei README.TXT.
|
Trados
Translator's
Workbench |
Voraussetzungen: Grundkenntnisse in MS Excel und Word
Einmal angenommen, Sie haben eine z. B. in MS Excel oder Word lesbare Liste (*.csv, *.txt, *.doc, *.rtf usw.) mit Fehlermeldungen, UI-Begriffen u. a. m. als Gegenüberstellung von fremdsprachlichen und muttersprachlichen Segmenten und möchten diese Liste als Trados-TM nutzen. Dann hilft dieser Trick:
Wir basteln uns ein Translation Memory
Trados-Import-TMs setzen auf einfache, in jedem Editor lesbare TXT-Dateien auf, die jedoch
- im Gegensatz zu Excel-Tabellen nicht zeilen-, sondern absatzorientiert sind, d. h. die Einträge stehen nicht neben-, sondern untereinander
- eine definierte Syntax voraussetzen, die wie folgt aussieht (wobei ¶ für eine Absatzschaltung steht):
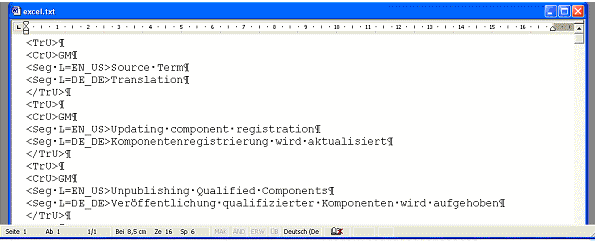
<TrU>¶ --> das Start-Tag
<CrD>17071994¶ --> CreationDate, das Erstellungsdatum
<CrU>MILLER¶ --> CreationUser, der Ersteller
<ChD>18071994¶ --> ChangeDate, das Änderungsdatum
<ChU>SMITH¶ --> ChangeUser, Benutzer, der eine Änderung vorgenommen hat
<UsD>18071994¶ --> UsedDate, das Datum der letzten Verwendung
<UsC>1¶ --> UsageCounter, Häufigkeit der Nutzung
<Att L=Client>Pro Software Inc.¶ --> der Kunde
<Att L=Domain>Software¶ --> das Fachgebiet
<Txt L=ID code>TR 1994/123 AB¶ --> die Projektkennung
<Seg L=EN_GB>How to construct a Translation Memory?¶ --> Ausgangstext
<Seg L=DE_DE>So basteln Sie ein Translation Memory¶ --> Zieltext
</TrU>¶ --> das End-Tag
Wirklich essenziell sind die Zeilen <TrU>, <CrU>, <Seg L=EN_GB>, <Seg L=DE_DE> und </TrU>, den Rest können Sie für unsere Zwecke getrost vergessen.
Bei Ihrer Import-Liste handelt sich allerdings um eine gewöhnliche zwei- oder mehrspaltige Excel-Tabelle mit fremdsprachlichen und muttersprachlichen Sätzen/Begriffen und ggf. Kommentaren, die nun aus dem zeilenorientierten in ein absatzorientiertes Format gebracht werden muss.
Gehen Sie hierzu wie folgt vor:
- Öffnen Sie die Liste in Excel mit der Importfunktion (Menü Daten > Externe Daten > Datei importieren).
- Löschen Sie alle Spalten, die Sie nicht benötigen (Kommentare, Hotkeys usw.).
- Fügen Sie vor der Source Term-Spalte zunächst eine Spalte hinzu.
- Tragen Sie in die erste Zelle der leeren Spalte (A1) <TrU> ein.
- Wechseln Sie mit Strg+Ende ans Ende der mit Source Text gefüllten Spalte B, markieren Sie von unten aus die links davon befindliche Leerspalte, und klicken Sie im Menü Bearbeiten auf Ausfüllen -> Unten, um den Inhalt der ersten Zelle in alle Zellen einzufügen.
Achtung, ganz wichtig: Prüfen Sie jede mit Text gefüllte Spalte mit der Tastenkombination "STRG+Ende" auf leere Zellen. Excel springt hierbei automatisch die nächste leere Zelle an. Sollten Sie leere Zellen finden, löschen Sie entweder den gesamten Eintrag (die gesamte Zeile!), weil die fremdsprachliche oder muttersprachliche Entsprechung fehlt, oder füllen Sie diese Zellen mit einem Wert wie "NONE". Enthält eine Spalte nämlich leere Zellen, verschiebt sich beim Export in die absatzorientierte Version der gesamte nachfolgende Text entsprechend, was dazu führt, dass die Importdatei unbrauchbar wird.
- Fügen Sie zwei weitere Spalten hinzu, und füllen Sie diese auf die vorstehend beschriebene Weise mit <CrU>, und <Seg L=EN_GB>.
Hinweis: Mit Ausfüllen können auch komplette Eintragsspalten wie <Att L=Client> oder <CrD> manuell erstellt werden.
- Fügen Sie hinter der Spalte <CrU> und der Source Text-Spalte jeweils eine weitere Spalte ein, füllen Sie die Spalte rechts neben <CrU> mit Ihrer Benutzerkennung und die Spalte rechts neben der Source Text-Spalte mit <Seg L=DE_DE>.
Hinweis: Hierbei ist EN_GB und DE_DE natürlich stellvertretend für die jeweils gewünschte Sprachrichtung zu sehen.
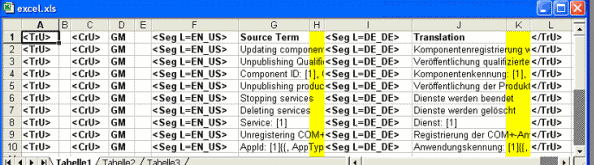
- Fügen Sie im nächsten Schritt vor zwei zusammengehörigen Spalten, d. h. EINEN Absatz bildenden Spalte, eine Leerspalte ein, also bspw. vor der Spalte mit <Seg L=EN_GB> und der mit dem englischen Ursprungstext und der Spalte mit <Seg L=DE_DE> und dem deutschen Zieltext. Ihre Excel-Liste sollte nun wie folgt aussehen:
Bitte beachten Sie, dass es sich bei den Spalte B, E, H und K um Leerspalten handelt, auch wenn das nicht unbedingt so aussieht...
Warum diese Spalten so wichtig sind, erfahren Sie im nächsten Schritt des Verfahrens.
- Speichern Sie die Datei in Excel als TXT-Datei (Text (Tabs getrennt) (*.txt)); ignorieren Sie hierbei alle Formatierungsabfragen von Excel und auch die letzte Abfrage, ob Sie denn nun wirklich...
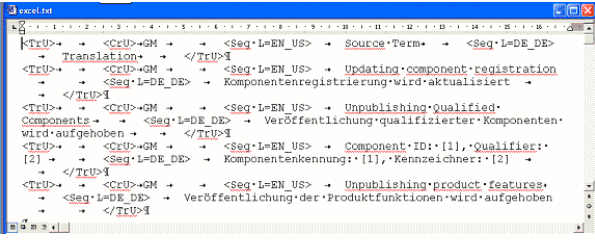
- Öffnen Sie die TXT-Datei in Word, und zeigen Sie unbedingt die nicht druckbaren Zeichen (Schaltfläche "¶") an.
Sie werden feststellen, dass in Word zwischen gefüllten Spalten jeweils ein Tabulator als Trennzeichen gesetzt wurde und dass Leerspalten ebenfalls mit einem Tabulator für die leere Spalte und einem Tabulator als Trennzeichen gekennzeichnet wurden, sodass die Zeile in Word wie folgt aussieht:
- Im nächsten Schritt hilft die Suchen/Ersetzen-Funktion von Word dabei, aus dem zeilenorientierten Format ein absatzorientiertes Format zu machen, denn nun werden zunächst die beiden aufeinander folgenden Tabulatoren gesucht und durch eine Absatzschaltung ersetzt.
Gehen Sie hierzu wie folgt vor:
- Geben Sie im Feld Suchen des Word-Suchdialogs "^t^t" und im Feld Ersetzen "^p" ein (Tipp: Schauen Sie je nach Word-Version (ich arbeite mit Word 2002) mal unter Sonstiges nach, welche Zeichenfolge für die Absatzschaltung steht, sonst kann es Überraschungen geben). Auf diese Weise werden zwei aufeinander folgende Tabulatoren durch eine Absatzschaltung ersetzt.
- Ersetzen Sie im nächsten Schritt den einzelnen Tabulator durch "nichts", d. h. lassen Sie das Feld Ersetzen einfach leer (jau, das geht!).
Ihr Word-Dokument sollte dann wie folgt aussehen:
Und damit ist es im Wesentlichen geschafft!
- Speichern Sie nun noch die Datei unter einem leicht veränderten Dateinamen (ggf. mit dem Zusatz "_word") als TXT-Datei ab (damit Sie evtl. Fehler weiterhin in Excel beheben können).
- Öffnen Sie Trados Workbench, und importieren Sie die soeben erstellte TXT-Datei (Menü Datei > Importieren). Über das Menü Datei > Datenpflege können Sie prüfen, ob der Import erfolgreich verlaufen ist.
Abschließend noch ein paar wichtige Hinweise:
- Wenn aus Ihrem Import ein komplett neues Memory werden soll, erstellen Sie einfach ein leeres TM und importieren die TXT-Datei. Die Workbench übernimmt dann automatisch alle Standardeinstellungen, Formatvorlagen und Schriftarten des zuletzt geöffneten TMs.
- Wenn Sie die Formatvorlagen und Schriftarten eines bestimmten anderen TMs übernehmen möchten, exportieren Sie dieses TM und kopieren Sie die RTF-Präambel, die am Anfang eines jeden Exports steht, in Ihre TXT-Datei. Ansonsten können Sie die RTF-Präambel vergessen.
- Die hier beschriebene Vorgehensweise funktioniert adäquat auch für den Eigenbau eines MultiTerm-Glossars für MultiTerm 5.5. Leider hat Trados die Terminologiedatenbank MultiTerm in der alten Form seit Version 6 der Workbench aus dem Paket genommen und durch MultiTermiX ersetzt, daher ist Benutzer gezwungen, die alten Version, also Trados Workbench 5.5, weiterhin installiert zu haben, wenn er mit der gewohnten Form der Terminologieerkennung weiterarbeiten möchte. Die Zusammenarbeit mit Trados Workbench 6.5 funktioniert allerdings nach wie vor reibungslos (was auch noch möglichst lange so bleiben sollte, denn mit MultiTermiX kann ich persönlich nicht wirklich was anfangen...)
|
Trados
TagEditor |
Voraussetzungen: Kenntnisse in TagEditor
Geht Ihnen das Korrekturlesen und die Rechtschreibprüfung in TagEditor auch ziemlich auf den Wecker und pflegen Sie zudem in Word nach Kunden organisierte Benutzerwörterbücher?
Dann versuchen Sie es mal mit dem folgenden Trick:
Rechtschreibung von TagEditor-Texten in MS Word prüfen
- Zeigen Sie das übersetzte Dokument in der Bearbeitungsumgebung von TagEditor an.
- Klicken Sie im Menü Bearbeiten auf Alles markieren und anschließend auf Kopieren, oder drücken Sie die Tastenkombination STRG+C.
- Öffnen Sie in MS Word eine neue, leere Datei.
- Klicken Sie in Word mit der rechten Maustaste auf die leere Seite, und klicken Sie dann auf Einfügen (alternativ können Sie auch im Menü Bearbeiten auf Einfügen klicken oder die Tastenkombination STRG+V verwenden).
- Nun wird das gesamte Dokument incl. des verborgenen fremdsprachlichen Textes angezeigt.
- Blenden Sie die nicht druckbaren Zeichen und damit den verborgenen Text aus (Schaltfläche "¶"), und starten Sie die Word-Rechtschreibprüfung (Extras -> Rechtschreibung und Grammatik). Alternativ können Sie in Word auch die automatische Rechtschreibprüfung aktivieren. Klicken Sie hierzu ggf. mit der rechten Maustaste auf das Buchsymbol in der Statusleiste, klicken Sie dann auf Optionen, und aktivieren Sie im nun angezeigten Dialogfeld Rechtschreibung und Grammatik das Kontrollkästchen Rechtschreibung während der Eingabe prüfen. Word versieht nun alle unbekannten Wörter mit roten, geschlängelten Linien (ab Word-Version 2000). Ansonsten kann das Dokument komfortabel mit der Word-Rechtschreibprüfung geprüft werden, und Sie können beliebige Benutzerwörterbücher vorgeben und erweitern.
- Nachteil: Wenn Sie einen Rechtschreibfehler finden, müssen Sie zu TagEditor wechseln und diesen dort korrigieren. Dieser Umstand wird jedoch durch die höhere Prüfgeschwindigkeit von Word problemlos wettgemacht.
Hinweis: Dieser Trick bietet noch eine Vielzahl weiterer Möglichkeiten, auf die ich hier nicht näher eingehen möchte (man muss ja nicht gleich alle Firmengeheimnisse verraten, oder ;-)?) Aber wenn Sie sich ein wenig damit auseinandersetzen, kommen Sie sicher von selbst drauf...
|
MultiTerm 5.5 |
Voraussetzungen: Kenntnisse in MS Word und Excel
Das Erstellen eigener MultiTerm-Glossare für MultiTerm 5.5 ist ebenso einfach wie das Erstellen von Translation Memories. Die Vorgehensweise ist unter Trados Translator's Workbench, "Wir basteln uns ein Translation Memory" im Detail beschrieben. Leider hat Trados die Terminologiedatenbank MultiTerm in der alten Form seit Version 6 der Workbench aus dem Paket genommen und durch MultiTermiX ersetzt, daher ist Benutzer gezwungen, die alten Version aus Trados Workbench 5.5 weiterhin installiert zu haben, wenn er mit der gewohnten Form der Terminologieerkennung weiterarbeiten möchte. Die Zusammenarbeit mit Trados Workbench 6.5 funktioniert allerdings nach wie vor reibungslos.
Der wesentliche Unterschied zum "selbst gestrickten" Translation Memory besteht in der Benennung der Datenbankfelder, die bei MultiTerm wie folgt aussieht:
**¶
<Anlagedatum>09.03.2004 - 11:20:22¶
<Angelegt von>super¶
<Änderungsdatum>09.03.2004 - 11:20:22¶
<Geändert von>super¶
<Eintragsklasse>1¶
<Grafik>¶
<Eintragsnummer>1¶
<English>How to create a MultiTerm glossary¶
<German>Wir basteln uns ein MultiTerm-Glossar¶
**¶
<Anlagedatum>09.03.2004 - 11:20:22¶
<Angelegt von>super¶
<Änderungsdatum>09.03.2004 - 11:20:22¶
<Geändert von>super¶
<Eintragsklasse>1¶
<Grafik>¶
<Eintragsnummer>1¶
<English>English term¶
<German>Deutscher Begriff¶
**¶
...
Essenziell hierbei sind die Zeilen **¶ <English>English term¶ und <German>Deutscher Begriff¶ wobei "¶" wieder für eine Zeilenschaltung steht (man beachte unbedingt auch die Zeile mit den beiden **, das sind die Datensatztrenner!!).
Wichtig hierbei:
- Beim Vorbereiten der Importdatei sollte man - besonders bei Microsoft-Glossaren - darauf achten, eventuell vorhandene HTML-Tags zu entfernen. Hierzu bietet sich der Texteditor TextPad an, der ein Makro zum Entfernen von Tags enthält.
- Außerdem ist der obige Hinweis unter Achtung, ganz wichtig auch hierbei unbedingt zu beachten.
- Des Weiteren sollte man beim Import darauf achten, doppelte Einträge zusammenzufassen, sonst gibt es 100 Mal den Eintrag "Cancel", und das MTW sprengt möglicherweise sämtliche Dimensionen.
Vorgehensweise zum Importieren und Zusammenfassen doppelter Einträge bei MT-Importen
- Legen Sie zunächst in MultiTerm eine neue Datenbank mit der Importdatei entsprechenden Feldnamen an. Sie müssen für das vorstehende Beispiel also zumindest die Indexfelder <English> und <German> anlegen. Ob Sie Attribut- und/oder Textfelder füllen, ist von der Importdatei abhängig, auf jeden Fall muss der Feldname in der Importdatei zu 100% dem Feldnamen in der MTW-Datenbankdefinition entsprechen. Speichern Sie die leere Datenbank unter dem gewünschten Namen.
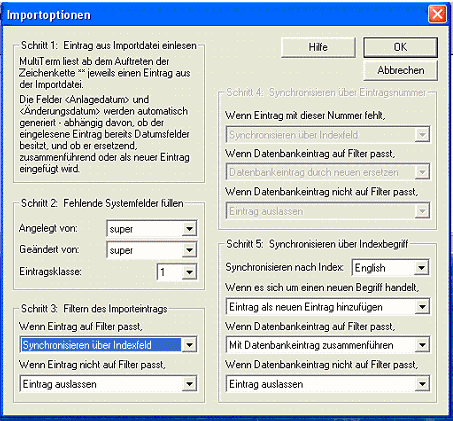
- Öffnen Sie die neue Datenbank in MTW, und klicken Sie im Menü Datei auf Importieren. Nun wird das nachstehende Dialogfeld angezeigt.
- Wenn Sie in der Importdatei vorkommende Duplikate zusammenfassen möchten, wählen Sie unter Schritt 3: Wenn Eintrag auf Filter passt in der Dropdown-Liste Synchronisieren über Indexfeld aus. Vergewissern Sie sich, dass unter Schritt 5 English angegeben ist.
- Klicken Sie auf OK. Jetzt können Sie die zu importierende Datei auswählen, und damit ist es im Wesentlichen getan. MultiTerm importiert die Datei nun als MTW-Glossar.
- Nach Abschluss des Imports müssen Sie natürlich noch den Fuzzy-Index erzeugen, damit auch die Suche funktioniert. Klicken Sie hierzu im Menü Datei auf Fuzzy-Index erzeugen.
|
IBM
Translation
Manager |
Voraussetzungen: Kenntnisse in IBM Translation Manager
Sie haben häufiger mit HTML-Texten in IBM Translation Manager zu tun? Auch in diesem Fall bietet sich folgender Workaround an:
- Übersetzen Sie den Text wie gewohnt, und zeigen Sie ihn anschließend in der TM-eigenen Vorschau an.
Hinweis:Wenn sich der Text aufgrund der IBM-eigenen Macken in der "Markup Table" nicht in der Vorschau anzeigen lässt, können Sie den Rest auch vergessen...
- Markieren Sie den in der Vorschau angezeigten Text mit gedrückter Maustaste, und kopieren Sie ihn mit der Tastenkombination STRG+C. Alternativ können Sie auch mit der rechten Maustaste arbeiten, auf Alles markieren klicken und den Text dann in Word einfügen.
- Öffnen Sie in Word ein neues, ggf. vorbereitetes, im Querformat formatiertes Dokument.
- Gehen Sie im Weiteren wie unter TagEditor ab Punkt 4 beschrieben vor.
- In Word können Sie auch nach den bei IBM verhassten doppelten Leerzeichen suchen, was in anderen Programmen nicht so ohne weiteres möglich ist... Auch hierbei gilt natürlich, dass gefundene Fehler in TM/2 korrigiert werden müssen, aber das dürfte sich von selbst verstehen.
|
TextPad |
Voraussetzungen: Allgemeine Kenntnisse im Umgang mit Computern
TextPad ist mit ca. 25 Euro incl. MwSt. ein preiswerter Texteditor, der sich zwar in erster Linie an Programmierer wendet, aber auch für Übersetzer einige unschlagbare Vorteile bietet. Hierzu gehören u. a. die Folgenden:
- Mehrere Dateien gleichzeitig durchsuchen. Diese Funktion ist besonders nützlich, wenn ein Begriff in mehreren (z. B. Glossar-)Dateien gleichzeitig gesucht werden soll. Hierbei ist das Dateiformat im Wesentlichen unerheblich, da TextPad so ziemlich alle gängigen Dateitypen incl. der Translation Manager-Formate FXP und EXP öffnen kann. Die jeweils zu durchsuchenden (Glossar-)Dateien sollten sich allerdings praktischerweise alle in einem Verzeichnis bzw. in Unterverzeichnissen dieses Verzeichnisses befinden. Im Dialogfeld In Dateien suchen (Menü Suchen) kann der Schalter Untergeordnete Ordner einbeziehen gesetzt werden. Im Feld In Dateien können Sie mehrere zu durchsuchende Dateitypen (z. B. "*.txt *.xls *.csv" oder "*.exp *.fxp") angeben bzw. einschränken. Wenn Sie auf die Schaltfläche Durchsuchen klicken, können Sie den Pfad zum gewünschten Verzeichnis auswählen, der dann im Feld In Dateien angegeben wird. Wenn Sie auf ein älteres Suchverzeichnis zurückgreifen möchten, öffnen Sie einfach die Dropdown-Liste des Feldes In Dateien. Praktisch ist auch die Möglichkeit, die Suchergebnisliste mit der einfachen Suche (F5) zu durchsuchen.
Hinweis: Beachten Sie, dass Sie in TextPad auch Änderungen an allen gängigen Dateiformaten vornehmen können, also nicht nur an Dateien, die auf dem einfachen TXT-Format basieren, wie TXT, XML, HTML, CSV, TSV usw., sondern auch beispielsweise an DOC- und XLS- und sogar an den sonst recht kapriziösen TagEditor-TTX-Dateien. Hierbei können die Dateien gleichzeitig in TextPad und in der Ursprungsanwendung geöffnet sein (wie sich das für ein Programmierer-Tool gehört ;-)), müssen nach dem Ändern und Speichern in TextPad allerdings in der Ursprungsanwendung neu geladen werden.
- Hyperlinks zu den Treffern in den durchsuchten Dateien. Wenn Sie in der Suchergebnisliste auf den Dateinamen am Zeilenanfang klicken, wird die Datei aufgerufen, in der der Begriff gefunden wurde, und so können Sie ggf. den Kontext zum Suchergebnis einsehen.
- Integriertes Makro "Strip Tags". Dieses Makro, das Sie über das Menü Konfiguration, Befehlsfolge Einstellungen > Makros in das Menü Makros übernehmen können, eignet sich hervorragend, um in spitzen Klammern befindliche Format-Tags aus Dateien zu löschen, um so bspw. ins CSV-Format konvertierte XLS-Glossardateien für den Import nach Multiterm vorzubereiten. Hiermit können auch Tags aus exportierten Trados Workbench-TMs entfernt werden.
Fazit: Hiermit habe ich nur einige der wirklich nützlichen Einsatzbereiche dieses Editors für Übersetzer genannt. Sie können unter dem oben aufgeführten Link eine Testversion des Programms herunterladen, weitere Informationen und zusätzliche Plug-Ins abrufen und sich selbst ein Bild von den ungeahnten Möglichkeiten machen, die dieses außerordentlich hilfreiche Programm bietet.
In diesem Zusammenhang möchte ich an alle Benutzer, die dieses oder andere Shareware-Programme regelmäßig nutzen, von den gebotenen Funktionen profitieren und mit dem Tool zufrieden sind, appellieren, die Programme nach der Testphase dann auch zu kaufen - der Preis ist vergleichsweise gering, und insbesondere die Freelancer unter uns sollten nicht vergessen, dass wir alle für unsere Arbeit bezahlt werden wollen!
|